前回まで、SVCを使って分類をしてきましたが、画像の機械学習に強いとされるDeepLearningを用いて分類をしてみたいと思います。
通常の機械学習との違い
DeepLearningは機械学習の一種ですが、特徴量を人間が決めるのではなく、学習の中で特徴量も抽出していくところが通常の機械学習とは異なります。
通常、機械学習では、データ分析等により人間が特徴量を抽出して、それをもとに学習を行います。例えば、こちらでは画像から主成分分析を行い、その分析結果から学習を行いました。
DeepLearningでは、人間が特徴量を分析して抽出する作業フェーズが不要で、前々回行った用な主成分分析等の特徴量分析フェーズは不要となります。(必要な前処理やデータの取捨選択は必要ですが。)
ひとまず、DeepLearningってどんなものかを知るために、モデル定義は引用して学習させてみたいと思います。
ライブラリ選定
今回、ライブラリは使いやすくて簡単なAPIが提供されているとされるKerasを使ってみたいと思います。人気上昇中のPyTorchも後程使ってみたいと思いますが、まずは初心者にやさしいところから入ります。
データ検証方法
これまでのSVCを用いた分類学習同様、ホールドアウト法を用います。
モデルの作成
モデルは、Kerasのチュートリアルから、モデルVGG-likeなconvnetモデルを引用して使うことにします。最適化関数と損失関数も以下の通り。
・最適化関数 : 確率的勾配降下法(SGD)
シンプルな最適化関数で須賀、学習には時間がかかるようです。
ハイパーパラメータもチュートリアルの値をそのまま使ってみましょう。
よく使われる値のようです。
・損失関数 : 交差エントロピー誤差
分類学習によく用いられる損失関数です。
学習データに合わせてモデルを変更
引用してきたモデルを今回の学習データに合うように、以下の変更を行いました。
- モデル流用したので、今回の入力データに合わせて入力層の数を画像の水平・垂直サイズに合わせる。
- 出力層の数をカテゴリ数(今回のデータは5人を分類するので5)に合わせる。
モデルに合わせて学習データの変更
- 学習データはサンプル数×一次元データなので、サンプル数×水平サイズ×垂直サイズ×チャネル数に変換(reshape)します。
- 出力データのターゲット変数をカテゴリ変数に変換します。(One-Hot Encoding)Kerasのto_categoricalモジュールを使用しました。
学習結果
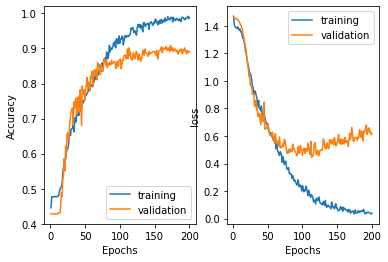
前回の正解率は0.79でした。今回CNNを用いて学習した結果、0.89とかなり向上しました。
但し、学習を繰り返していくと、train loss に対し test lossが乖離していっていくという結果になりました。これは、モデルが学習用データに適合しすぎている、過学習という状態になっていると思われます。エポック数50-60辺りが最も学習・検証共に損失が最も少ないところになります。
過学習回避のためにモデル変更が必要ということでしょうか。
次回は最適化関数を変更して、学習速度に変化があるか?試してみたいと思います。
「Pythonと機械学習であそぼう(Kerasを使ってDeepLearningモデルを実装してみよう)」への4件のフィードバック
ピンバック: Pythonと機械学習であそぼう(TensorBoardを使ってみよう) | ぼちぼちいこらい
ピンバック: Pythonと機械学習であそぼう(作成したCNN学習モデルを保存しておこう) | ぼちぼちいこらい
ピンバック: Pythonと機械学習であそぼう(Kerasを使ってDeepLearningモデルを実装、最適化関数を変更してみよう) | ぼちぼちいこらい
ピンバック: Pythonと機械学習であそぼう(データ標準化で分類学習の精度を向上してみよう) | ぼちぼちいこらい