前回は、学習の準備のために、lfwデータセットを取得しました。
今回は、どのような学習手法をとるのか?を決めていこうと思います。
教師あり学習
Scikit-learn UserGuideの教師あり学習(Supervised learning)の章を見ると、以下の通り、多くの項目が並んでいます。
- 1.1. Linear Models
- 1.2. Linear and Quadratic Discriminant Analysis
- 1.3. Kernel ridge regression
- 1.4. Support Vector Machines
- 1.5. Stochastic Gradient Descent
- 1.6. Nearest Neighbors
- 1.7. Gaussian Processes
- 1.8. Cross decomposition
- 1.9. Naive Bayes
- 1.10. Decision Trees
- 1.11. Ensemble methods
- 1.12. Multiclass and multilabel algorithms
- 1.13. Feature selection
- 1.14. Semi-Supervised
- 1.15. Isotonic regression
- 1.16. Probability calibration
- 1.17. Neural network models (supervised)
はて?
どれを使えばいいのやら?聞いたことがあるもの、ないもの
初心者には難しいですね。
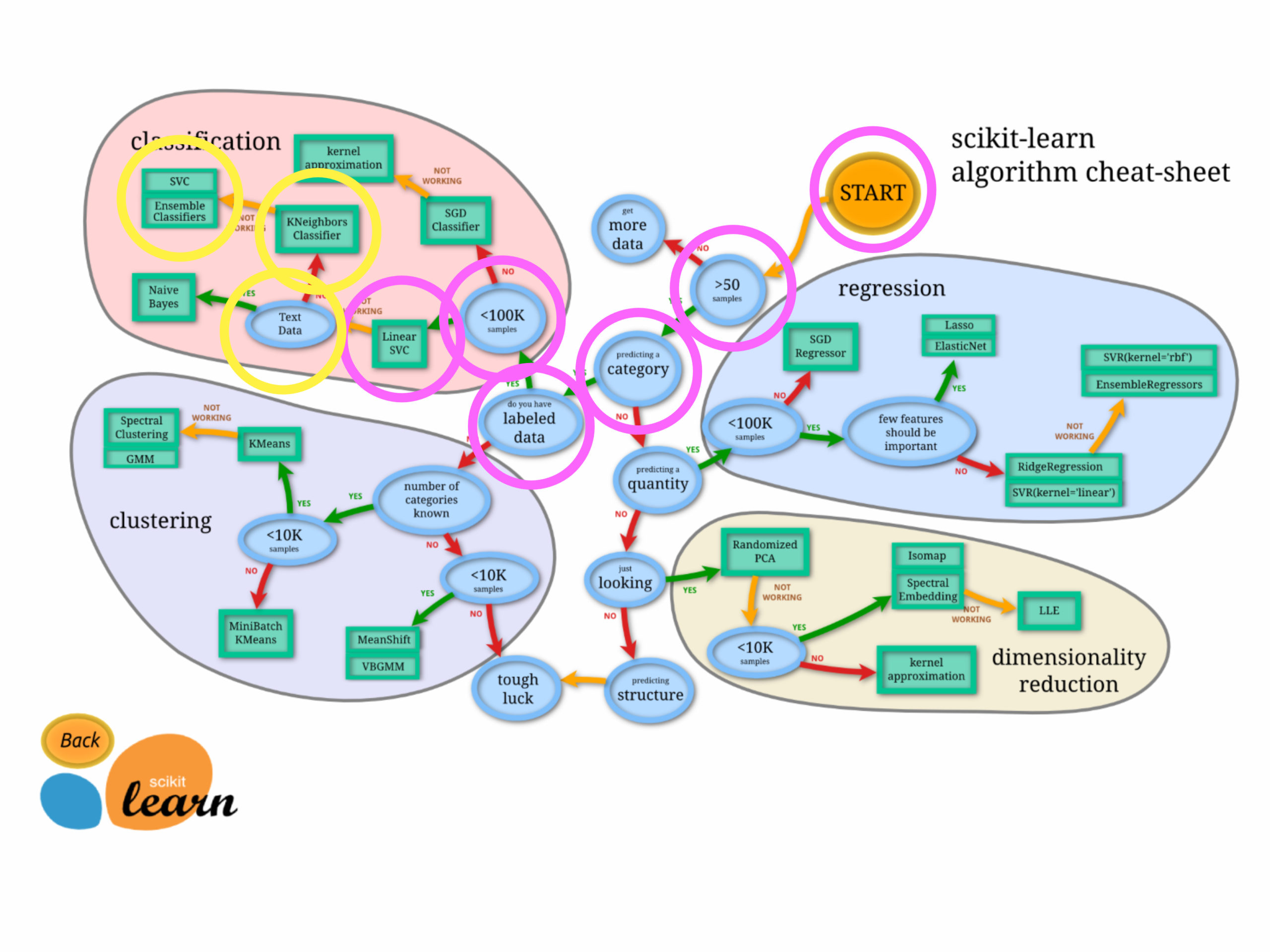
scikit-learn algorithm cheat-sheet
Scikit-learnのチュートリアルに、手法を選択するためのフローチャートがありますので、これを参考にしてみたいと思います。

前回準備したlfwデータセットで顔認識の機械学習をしたいと思いますので、フローチャートに従って判断してみました。
フローチャートに従って判定していくと・・・
- サンプル数は50より大きい・・・Yes!!
- カテゴリ予測・・・Yes!!
- ラベル付きデータ・・・Yes!!
- 100,000サンプル未満・・・1140サンプルなのでYes!!

ということで、フローチャートに従うと、まず、LinearSVCで実施せよ!!とのことですが・・・