各種オンライン講座等を活用することで、いろいろ断片的だった部分がつながったりして、少し前進できた気がします。
実際に一度動作させることで、もう少しイメージがつかめるのではないか?
機械学習のライブラリを使って、学習モデルの生成・最適化・評価といった一連の動作をさせてみたいと思います。
そのためには、学習させるための画像と正解ラベルのデータが必要です。
scikit-learn 機械学習用データセット
今回はScikit-learnで用意されている画像データを使ってみたいと思います。
scikit-learnには、機械学習の処理ライブラリだけではなく、いくつかのデータセットが用意されていおり、こちらのサイトに説明があります。
- ボストンの家賃データ(回帰分析用)
- ユリの花データ(分類用)
- 糖尿病データ(回帰分析用)
- 手書き数値データ(分類用)
- 運動能力データ(多変量解析用)
- ワインデータ(分類用)
- 乳がんデータ(分類)
このように、目的別にいくつかのデートセットが用意されています。さらに、人物顔データセットも用意されています。今回は、人物顔のデータセットをダウンロードして、分類の機械学習を行ってみたいと思います。
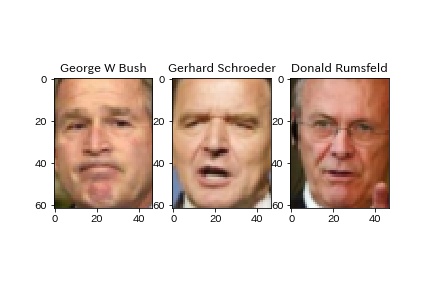
Labeled Faces in the Wild
scikit-learnのデータセットの
7. Dataset loading utilities
7.3. Real world datasets
から、lfw(labeled Faces in the Wild)を取得して、データの中身がどういうものかを少し見てみました。
グレースケールの画像を指定することも可能です。
まずはこちらで少し機械学習の動きを簡単な実装をしながら見てみたいと思います。
次回は、どの機械学習の手法を使うか?考えてみたいと思います。
「Pythonと機械学習であそぼう(機械学習用のデータセットを入手しよう)」への1件のフィードバック
ピンバック: Pythonと機械学習であそぼう(機械学習について学ぼう) | ぼちぼちいこらい